Preventing Cache Stampedes
1/21/2023I got to do some fun stuff at work involving cache expiration algorithms. It's not every day I get to cite a paper in a merge request.
We have a lot of traffic and caching is a key component of making things fast. Some data can be safely cached for 10 minutes for slowly changing values. Typically, after the 10 minutes is up, the next request would be "unlucky" and have to calculate the new value. The problem is when many workers try to refresh the value at once because the cache expired and the new value hasn't been set yet. During that time, the delta time, every request will also try to refresh. This will cause load spikes and periodic bad experiences for users of the website and API. That's called a cache stampede and can result in bursts of high load on the database and other infrastructure.
The previous algorithm
Some old legacy code had solved the stampede problem by using an artificially long TTL and the timestamp of the real expiration. Each worker on checking the cache would have to also check the expiration time. If the cache was supposed to be expired, that worker would write the cache key with a new future expiration time to prevent a cache stampede during recalculation, and then write again when it had finished recalculating.
This approach worked for many years, but recently we noticed that setting new cache values would sometimes take 50ms or longer. This was because the cache was full of artificially long-lived values. If nothing ever requests a key again, it can't be expired by the cache because of the long TTL. Memcached has a background thread to do this without impacting users but that can’t work if the TTL is not set correctly.

Memcached memory usage was typically high. Worse, new releases (with an empty cache) were often faster over all until memory in the cache was filled and evictions started. This is because setting new memory required memcached to evict the least recently used value, which means iterating over all the memory in a slab to find the least used key. This will block cache writers until memory is found.
Probabilistic Early Expiration
There are various ways to fix this. Sometimes people's first reaction is to try to use an exclusive lock so there's only one worker refreshing a value at a time. This can work in some situations but is hard to make work on distributed systems. It also has problems if that worker encounters an error and fails release the lock. Website response times will still be spikey as workers block on the cache recalc, though it does prevent all of them refreshing at the same time.
A better strategy is to use a probabilistic approach. That is, each worker will calculate a probability of refresh. If the threshold is exceeded, that worker will then refresh the cache.
This would mean that values will be calculated ahead of the TTL, but it means a low likelihood of a stampede. In the implementation of XFetch, the probability of refresh exponentially increases until the TTL time.

In my initial implementation, we didn't necessarily know how long it would take to recalculate cache (delta), but assumed it was typically less than a second. I used the value of 100 here to more aggressively recalculate ahead of the TTL. Under test, I had found the stampede size to be higher than hoped given a lot of traffic. By multiplying by a larger delta, I could spread out that probability and get the typical stampede size down to less than 3.
Stampede size with this algorithm is highly variable on traffic and testing methodology, so I was simulating expected load on a single pod.
$expiry = $time + $ttl;
$delta = 100; // guess time to recalc, this can be used to scale
$rand = mt_rand() / mt_getrandmax();
if ($rand === 0) {
// log(0) == -Inf
$rand = 0.0000000000000001;
}
return $this->currentTime() - $delta * log($rand) >= $expiry;
Improvements
In code review, a coworker helpfully pointed out that I may have been too aggressive with the probabilities. We didn't have this use case at the time, but it would be possible for future code to have a short TTL and a long delta, which would lead to an uncomfortably early expiration. The paper calls this the "gap" time, the amount of time between the refresh and the actual expiration time.
Indeed, when I tested $delta = 4 and $ttl = 60 (by calling an API with a sleep function), the average refresh time
was 34 seconds. Not terrible and wouldn't necessarily cause a problem in production, but still a much larger gap than
expected. Even after modifying the cache code to track the real delta time instead of guessing, the gap was still high.
I tested various combinations of beta and delta and found it difficult to find a good beta value that worked in all
situations.
On re-reading the paper's testing section, I realized they had this problem as well. They just weren't concerned with gap times ranging in the minutes because their use case was an hour long TTL and a comparatively huge delta.
What I really wanted was for the probably of a refresh to approach 1 at the expiration time minus the time it'd take to recalculate, not the TTL as XFetch was written. This allowed me to be a lot more precise about when to refresh and it worked better for shorter TTLs. The updated code looked something like this:
$beta = 2;
$expiry = $time + $ttl;
$rand = mt_rand() / mt_getrandmax();
if ($rand === 0) {
// log(0) == -Inf
$rand = 0.0000000000000001;
}
return $this->currentTime() + $delta - $beta * log($rand) >= $expiry;
Under test this averaged a 54s refresh (completion) time, which was a very short gap of 6s and a stampede size of 1.
Production
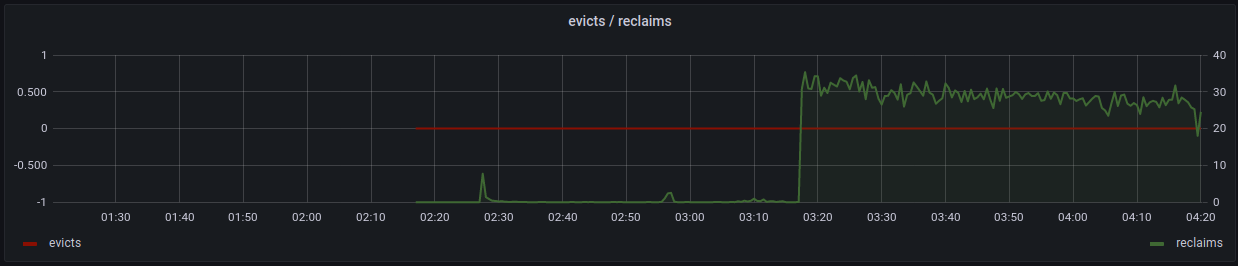
This performed as expected in production, rather than high evictions and blocked writers, cache evictions dropped to 0. The below graph was taken after the release and as cache began to expire, memcached was able to do its job and free memory without blocking new writers. Memory usage also dropped to 25% and no latency spikes were observed.
I really enjoyed working on this and seeing the impact it had on an infrastructure problem. I typically work on product things but in this case the infrastructure was causing a bad user experience for too many people.